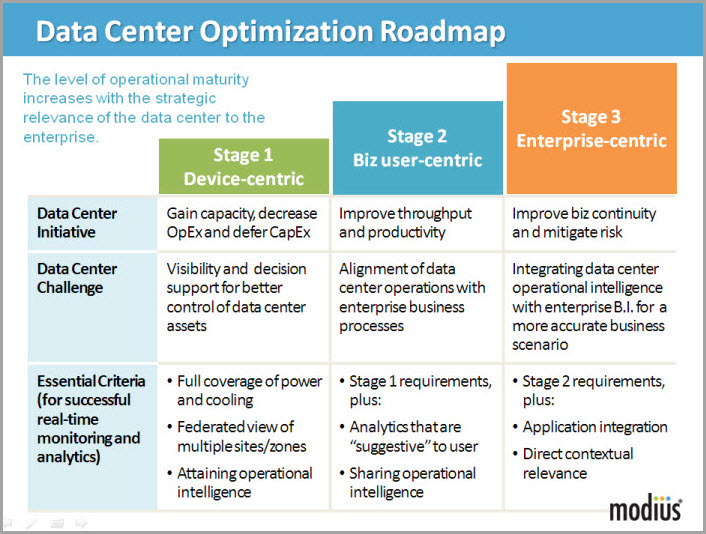
Speaking to a standing-room-only audience at the 2011 Uptime Symposium, Modius CEO Craig Compiano talked about the evolution of data center maturity: keeping pace with business needs. He introduced Modius’ Data Center Optimization Roadmap, which illustrates how optimization capabilities can be logically divided and accomplished in incremental steps. These steps deliver tangible benefits that continue to be leveraged as data center capabilities mature and become more relevant to the enterprise it supports.

The value of this roadmap immediately resonates with anyone who has worked on a long-term IT project—like managing a data center, for instance. All too often failures occur because the project team did not have the foresight to discern how their technology implementation might evolve over time. Consequently, early investments become outmoded in about 18 months, and the stakeholders are confronted with rapidly diminishing returns on their investment, if they are ever fully realized at all.
Instead of thinking about adding functionality and capacity in terms of incremental hardware (e.g., adding more servers), consider maximizing the capacity of your current investment, such that resources are more economically utilized within the existing infrastructure (e.g., identifying stranded capacity). Let’s take a closer look at the Data Center Optimization Roadmap to see how this can be accomplished.
Click Image to Zoom
Modius sees the operational maturity of the data center in three stages. At each stage, the operational maturity of the data center increases with the level of strategic relevance it provides to the enterprise.
Stage 1 is device-centric: Continuous optimization requires gaining visibility of data center assets—from racks to CRACs—including those assets at different sites. Whether assets are being monitored from across the hall or across the continent, granular visibility into each device is necessary to understand how resources are being utilized by themselves and within the larger system that is the network.
The only way to accomplish this is by measuring where, when, and at what rate power is being consumed. Device-level visibility enables us to eke every kW of power, to maintain safe yet miserly cooling levels, and to ensure every square foot of the data center floor is effectively being used. (Walking around the data center floor and spot checking metered readings is no longer effective.)
With this device-level insight, you can identify tactical ways of maximizing utilization or reducing energy consumption. And, as a result of more efficient use of resources, businesses can defer capital expenses.
Stage 2 is business user-centric: The second stage in advancing data center optimization requires the alignment of data center performance information with the business user’s requirements. (By business users, we mean either internal users, such as a department or a cost center at an enterprise, or external users, such as the customers at a co-lo facility.) This level of optimization can only be achieved once the mechanisms are in place to ensure visibility of data center assets by their end users, per Stage 1. For example, monitoring and decision support tools must have the ability to logically sort and filter equipment by business groups, rather than the physical location of equipment in a data center (e.g., racks, rows or zones). Likewise, these tools must be flexible to accommodate business-driven time periods, rather than time periods convenient only to data center operations.
By enabling this business user-centric view—that is, by making data center operational intelligence meaningful to the end-users of the data center—IT and Facility personnel can now engage business users in a productive dialog about how their business requirements impact data center resources. Now, data center managers can begin to optimize throughput and productivity in a way that is meaningful to the business, which significantly advances the strategic relevance of the data center to the enterprise.
Stage 3 is enterprise-centric: The third stage in advancing data center optimization requires making available data center operational intelligence with enterprise business intelligence (BI). We are not suggesting anything complicated or unwieldy, only that by including data center performance and resource data, enterprises can provide a more complete picture of the true cost of doing business. By aligning “back end” data center operations with “front end” enterprise business processes, we can understand how market pressures impact the infrastructure, which in turn helps improve business continuity and mitigate risk.
For example, product and marketing managers can now have visibility into the data center resources supporting their web services. They can drill down to their back-office systems and account for the commissioning and decommissioning servers, plus the energy and human capital required to run and manage those services. Another example: supply chain managers or sourcing managers can now see where and at what rate energy is being consumed across data center operations, enterprise-wide. This enables them to make better decisions about where to source energy, in addition to forecasting how much is needed.
These improvements are evidenced by enterprise agility—enterprises that can rapidly respond to a dynamic market and economic pressures. It is at this stage of maturity in data center operations that a data center can have a profound impact on whether a business can compete and win in the marketplace.
 Different isn't always better, but better is always different.
Different isn't always better, but better is always different.
Marina Thiry, Director of Product Marketing
 Can’t measure data-center heat load, but have good electrical sub-metering. Use electrical power as a substitute for cooling load. Every watt going in ends up as heat, and there usually aren’t too many people in the space routinely. Works best if you’re also measuring the power to all other non-data-center cooled space. The ratio of the two will get you close to the ratio of their cooling loads. If there are people in a space routinely, add 1 kWh of load per head per 8-hr day of light office work.
Can’t measure data-center heat load, but have good electrical sub-metering. Use electrical power as a substitute for cooling load. Every watt going in ends up as heat, and there usually aren’t too many people in the space routinely. Works best if you’re also measuring the power to all other non-data-center cooled space. The ratio of the two will get you close to the ratio of their cooling loads. If there are people in a space routinely, add 1 kWh of load per head per 8-hr day of light office work.