In the news recently, there has been a lot of discussion around a new category of software tools focusing on unified facilities and IT management in the data center. These tools have been labeled by Gartner as Data Center Infrastructure Management (DCIM), of which Modius OpenData is a leading example (according to Gartner).
In the news recently, there has been a lot of discussion around a new category of software tools focusing on unified facilities and IT management in the data center. These tools have been labeled by Gartner as Data Center Infrastructure Management (DCIM), of which Modius OpenData is a leading example (according to Gartner).
In reality, there are multiple types of tools in this category - Asset Management systems and Real-time Monitoring systems like Modius. The easiest way to understand the differences is to reflect on two key elements:
- How the tools get the data?
- And how time critical is the data?
Generally speaking, data center Asset Management systems, like nlyte, Vista, Asset-Point, Alphapoint, etc., are all reliant on 3rd party sources to either facilitate data entry of IT device 'face plate' specs, or are fed collected data for post process integration.
The data processing part is what these systems do very effectively, in that they can build a virtual model of the data center and can often predict what will happen to the model based on equipment 'move, add or change' (MAC). These products are also strong at utilizing that model to build capacity plans for physical infrastructure, specifically power, cooling, space, ports, and weight.
To ensure that the data used is as reliable as possible the higher priced systems contain full work-flow and ticketing engines. The theory being that by putting in repeatable processes and adhering to them, the MAC will be entered correctly in the system. To this day, I have not seen a single deployed system that is 100% accurate. But for the purposes they are designed for (capacity and change management), these systems work quite well.
![]() However, these systems are typically not used for real-time alarm processing and notification as they are not, 1) Real-time, and 2) Always accurate.
However, these systems are typically not used for real-time alarm processing and notification as they are not, 1) Real-time, and 2) Always accurate.
Modius takes a different approach. As compared with Asset Management tools, Modius gets its data DIRECTLY from the source (i.e. the device) by communicating in its native protocol (like Modbus, BACnet, and SNMP) versus theoretical 'face plate' data from 3rd party sources. The frequency of data collection can vary from 1 poll per minute, to 4 times a minute (standard), all the way down to the ½ second. This data is then collected, correlated, alarmed, stored and can be reported over minutes, hours, days, weeks, months or years. The main outputs of this data are twofold:
 Centralized alarm management across all categories of equipment (power, cooling, environmental sensors, IT devices, etc.)
Centralized alarm management across all categories of equipment (power, cooling, environmental sensors, IT devices, etc.)- Correlated performance measurement and reporting across various catagories (e.g. rack, row, zone, site, business unit, etc.)
Modius has pioneered real-time, multi-protocol data collection because the system has to be accurate 100% of the time. Any issue in data center infrastructure performance could lead to a failure that could affect the entire infrastructure. This data is also essential in optimizing the infrastructure in order to lower cooling costs, increase capacity, and better management equipment.
Both types of tools -- Asset Management tools and Real-time Monitoring systems -- possess high value to data center operators utilizing different capabilities. The Asset tools are great for planning, documenting, and determining the impacts of changes in the data center. Modius real-time monitoring interrogates the critical infrastructure to make sure systems are operating correctly, within environmental tolerances, and established redundancies. Both are complimentary tools in maintaining optimal data center performance.
Because of this inherent synergy, Modius actively integrates with as many Asset Management tools as possible, and supports a robust web services interface for bi-directional data integration. To find out more, please feel free to contact Modius directly at info@modius.com.
 As discussed previously in earlier blogs, VFD’s will provide the throttle necessary to achieve energy efficiency. Several states, including California, are providing rebated for installing VFD’s and pay for nearly 60% of the cost of the equipment (for more information on this topic, contact us at
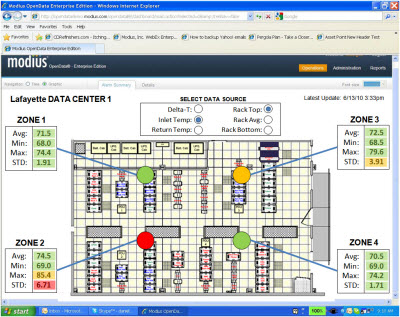
As discussed previously in earlier blogs, VFD’s will provide the throttle necessary to achieve energy efficiency. Several states, including California, are providing rebated for installing VFD’s and pay for nearly 60% of the cost of the equipment (for more information on this topic, contact us at  In order to get the best possible data about what is actually happening at the rack level, there are several practical ways to extend your temperature and humidity instrumentation across your environment. This may include not only deploying the latest generation of inexpensive wirefree environmental sensors, as well as unifying data that is already being captured by existing instrumentation from wired, wireless, power strip-based or server-based instrumentation.
In order to get the best possible data about what is actually happening at the rack level, there are several practical ways to extend your temperature and humidity instrumentation across your environment. This may include not only deploying the latest generation of inexpensive wirefree environmental sensors, as well as unifying data that is already being captured by existing instrumentation from wired, wireless, power strip-based or server-based instrumentation.