Early last year, Gartner published a short research note that has since had an unexpectedly significant impact on the vocabulary of data center management professionals. Prior to March 2010, which is when Dave Cappuccio published “Beyond IT,” the term ‘data center infrastructure management’ (or DCIM) was rarely ever used. Instead, the most common terms describing software to manage power and cooling infrastructure were ‘data center monitoring’ or ‘data center asset tracking’ or ‘BMS for data center.’ We know this, because here at Modius we use an inbound analytics application to track the search terms by internet users to find our web site.
By end of last month (April 2011), the simple search term DCIM has outpaced all of them! Go to any web site keyword tracking service (e.g. www.hubspot.com) and see for yourself. In April, there were over 10,000 queries for DCIM on one of the major search engines alone. As a longtime software vendor for the enterprise, I find it hard to remember ever seeing a new title for a software category emerge so suddenly and so prominently. Now everyone uses it. Every week it seems there is a new vendor claiming DCIM credentials.
From our perspective here at Modius, we find this amusing, because we have been offering the same kind of functionality from our flagship software product OpenData since long before the term DCIM has been around. Nonetheless, we know find ourselves in a maelstrom of interest as this new software label gains more buzz and credibility. So what is exactly is DCIM?
The graphic below is my summary of the major points from the original research note. Note that DCIM was originally positioned as filling a gap between the major categories of IT Systems Management and Building Management or Building Automation Systems.
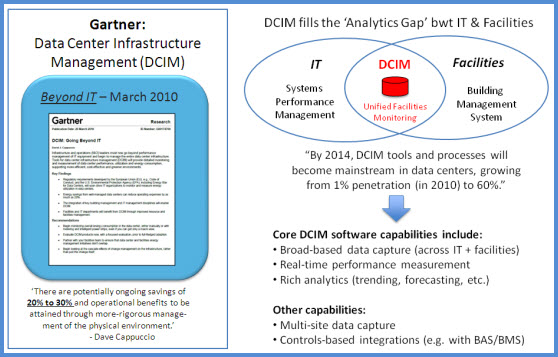
As more and more software vendors have jumped on the DCIM bandwagon, we have noticed that 4 distinct sub-categories, or segments, have emerged:
- Monitoring tools for centralized alarm management and real-time performance tracking of diverse types of equipment across the power and cooling chains (e.g., Modius OpenData)
- Calendar-based tools for tracking equipment lifecycles (i.e., particularly with respect to recording original shipment documentation, maintenance events, depreciation schedules, etc.)
- Workflow tools specifically designed around data center planning and change management (e.g., “If I put this server in this rack, what is the impact on my power & cooling systems?”)
- Tools for control and automation of cooling sub-systems (e.g., usually computer room air conditioning systems or air-handling units)
At Modius, we focus on segment #1. We find the challenges to connecting to a diverse population of power and cooling equipment from a range of vendors is a difficult task in and of itself. Not only are the interface challenges non-trivial (e.g., translation across multiple communication protocols), but the data storage and management problems associated with collecting this much data are also significant.
Moreover, we are puzzled at the number of segment #3 applications which position themselves as DCIM tools, yet don’t have any real-time data capabilities of any significance. We believe for those systems to be the most effective, they really need to leverage a monitoring tool in segment #1.
So, in conclusion--and not surprisingly--we define the DCIM software category as a collection of different types of tools for different purposes, depending on your business objectives. But one point we like to stress to all of our customers is that we believe that real-time performance tracking is the foundation of this category, and we are looking to either build out new capabilities over time, or to partner with other software companies that are pursuing other areas of DCIM functionality. After all, improving the performance of a facility is the ultimate end goal, and we before we do anything else, we can’t manage what we can’t measure.
 Can’t measure data-center heat load, but have good electrical sub-metering. Use electrical power as a substitute for cooling load. Every watt going in ends up as heat, and there usually aren’t too many people in the space routinely. Works best if you’re also measuring the power to all other non-data-center cooled space. The ratio of the two will get you close to the ratio of their cooling loads. If there are people in a space routinely, add 1 kWh of load per head per 8-hr day of light office work.
Can’t measure data-center heat load, but have good electrical sub-metering. Use electrical power as a substitute for cooling load. Every watt going in ends up as heat, and there usually aren’t too many people in the space routinely. Works best if you’re also measuring the power to all other non-data-center cooled space. The ratio of the two will get you close to the ratio of their cooling loads. If there are people in a space routinely, add 1 kWh of load per head per 8-hr day of light office work.

 The office floors above the data center all have essentially identical layouts, consisting of conference rooms, cube farms, and the occasional honest-to-goodness office. Centrally located on each floor is an efficient, well-maintained kitchenette. In each kitchenette is a water cooler. Like many of its kind where the tap water is potable, this water cooler is plumbed directly to the sink. The ¼-inch white plastic tubing is anchored in place with small brass ferrules. This system has been doing yeoman's work for years, reliably delivering chilled, filtered drinking water to the employees with better than 99% up time, allowing for scheduled maintenance.
The office floors above the data center all have essentially identical layouts, consisting of conference rooms, cube farms, and the occasional honest-to-goodness office. Centrally located on each floor is an efficient, well-maintained kitchenette. In each kitchenette is a water cooler. Like many of its kind where the tap water is potable, this water cooler is plumbed directly to the sink. The ¼-inch white plastic tubing is anchored in place with small brass ferrules. This system has been doing yeoman's work for years, reliably delivering chilled, filtered drinking water to the employees with better than 99% up time, allowing for scheduled maintenance. Meanwhile, back in the kitchenette, the leak is discovered during a security sweep and the flow is cut off, but human intervention has come too late for the electronics down below. Power redundancy saved all servers that were not directly water-damaged, so only a few internal business applications took an uptime hit, along with the kitchenette. Over $100,000 of damage, thanks to the failure of a few pennies of plastic tubing in a “non-critical” part of the facility.
Meanwhile, back in the kitchenette, the leak is discovered during a security sweep and the flow is cut off, but human intervention has come too late for the electronics down below. Power redundancy saved all servers that were not directly water-damaged, so only a few internal business applications took an uptime hit, along with the kitchenette. Over $100,000 of damage, thanks to the failure of a few pennies of plastic tubing in a “non-critical” part of the facility. Physical Layout – Just as one manages power usage in a home by turning out the lights in unoccupied rooms, one can also manage data center power. By compartmentalizing the data center into energy zones or modules, with independent controls for power, cooling, and humidity, each module can be independently “lit up” as needed. Modularization can be achieved by erecting walls, hanging containment curtains, or by using pods, i.e., enclosed compartments of IT racks that employ a centralized environmental management system to provide cool air at intake and keep warm air at the exhaust.
Physical Layout – Just as one manages power usage in a home by turning out the lights in unoccupied rooms, one can also manage data center power. By compartmentalizing the data center into energy zones or modules, with independent controls for power, cooling, and humidity, each module can be independently “lit up” as needed. Modularization can be achieved by erecting walls, hanging containment curtains, or by using pods, i.e., enclosed compartments of IT racks that employ a centralized environmental management system to provide cool air at intake and keep warm air at the exhaust. Power and Cooling Infrastructure – Right-sizing the facilities infrastructure follows the modularization of the physical layout. As the modules—zones or pods—are created
Power and Cooling Infrastructure – Right-sizing the facilities infrastructure follows the modularization of the physical layout. As the modules—zones or pods—are created