Just read about a new innovative way to address the cooling requirements within the data center worthy of mention here. As no surprise, the data center energy management challenge has many parts to it, and as we all are seeing, MANY different new solutions will be required and combined over time to fully embrace the REALM OF WHAT'S POSSIBLE. Oh sure, everyone will have their favorite 'energy saver' technology. We saw this happen with Virtualization, and we saw it happen with Variable Frequency Drive controllers for data center fans.
Well, what if we take a look WITHIN the servers themselves and consider the opportunities there? Does the WHOLE server generate heat? NO. Key parts do, like the CPU, chipset, VGA chip and Memory & controllers. So why do we have to BLOW SO MUCH air across the entire motherboard, using bigger expensive to operate fans? Wouldn't it be better to SPOT COOL just where the heat is? Reminder, the goal is to just move the heat away from the chips that generate heat. We don't need to move large volumes of air just for the thrill of air handling....
I have seen two competing advances in this space. One maturing approach has been adopted in 'trials' by some of the biggest server vendors. They offer liquid based micro heat exchanger equipped versions of some of their commercial server product lines. This means these special servers have included PLUMBING/cooling pipes into the server chassis themselves, and the circulating fluid moves the heat away from the server's heat-generating chips. Take a look right next to the LAN port and power plug in the back, and you'll see an inlet/outlet fitting for liquid! Basically fluid based heat removal. Humm, harkens back to the 80's when big IBM 390s were using water cooling when everyone else went to air. (As a note, fluid cooling is making a resergence as liquid cooling becomes popular once again...).
So now I see a new approach... 'solid state' air jets. Air jets? Yes really small air movers that are essentially silent, have no moving parts, and consume tiny bits of power. Turns out at least one vendor has created really small 'jets' which have proven that you can move LOTS of air without any moving parts. Yes, they are also really silent, and can magically create large amounts of air movement in really small spaces. Using this technology, you can target just the chips that need cooling with relative 'hurricanes', and then simply use small standard fans to carry this (now easily accessible) hot air out of the box.
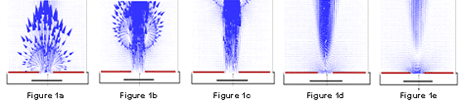
What results in savings does the spot jets achieve? In their published test, they reduced the standard high power fan speed from 9000 rpm to 6500 rpm, going from 108watts originally to only 62watts. Add back into this an estimated 10% energy cost for the air jets themselves, and the net savings for fans inside the box is about 30%. Remember, FANs account for nearly 47% of a data centers' entire cooling energy consumption, so reducing FAN speeds inside AND outside the boxes is critical to long term power savings.
Lastly, how do you know all your effort has paid off??? Monitor FAN speeds! I'll say it a million times, monitoring FAN speeds is very important. The slower the run, the less they consume. Monitor, Monitor, Monitor!!!